Randomforests And Bootstrap Aggregating
As we know in simple averaging methods RFs perform better than Bootstrap Aggregating or bagging by considerably reducing the high variance (see bias-variance tradeoff) of a single classifier by continuous independent sampling with replacement from the same distribution(dataset). This performance gain of RFs is described very well in this Leo Breiman(2001) paper and also in The Elements of Statistical Learning : Hastie,Tibshirani,Friedman in the section RandomForests.
I will briefly describe the idea of performance gain in Rfs over bagging here. Since in both the ensembling methods a single classifier(decision trees), which is very prone to high variance, when makes use of all the available features, it tends to over-fit since a more complex tree dependence structure is generated. Averaging over different classifiers, with low collinearity among them, decreases the over-all complexity of the final ensembled model. But including all the feature is not a good idea, since all the features might not help much in overall information gain for individual classifier and many a time can prove to be a source of noise. To overcome this problem L. Breiman proposed the idea of selecting features randomly from some fixed number of features..
Code
In the following code snippet, oob error is calculated for each estimator that is being added to the classifier grown on Boston_housing_data and a graph is plotted on matplotlib for the same.
Note : I have used sqrt(Number of features) as max_feature which is the recommended number of features to be sampled from the distribution.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 | |
OOb_Score Vs n_estimators Plot
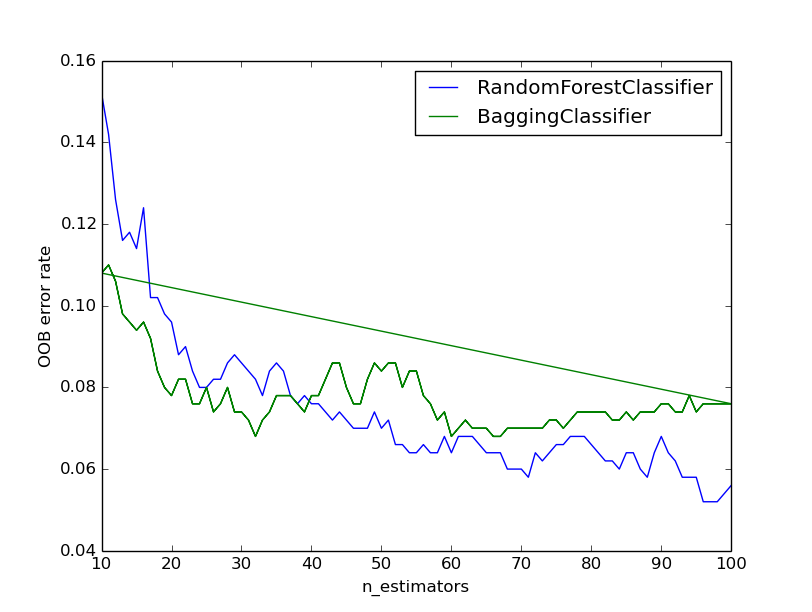
In the above plot we tried to plot out-of-bag error(error estimated over currently ensembled classifiers with data point not in dataset or out of the bag) on Y-axis and X-axis shows “n_estimator” which describes the number of estimator ensembled till now. As the number of estimator increase overall variance reduces for both the ensembling methods. But Random Forest is the clear winner all the way while growing the forest where #Tress equals 100. This shows how random feature selection generalizes the final model and reduces over-fitting and variance than choosing all the features.
Also remember,the performance of RFs is very much dependent upon the collinearity between the estimators being grown for the forests. Lesser the collinearity, better is the performance of the estimator.